A deep learning model that creates images from text promts
In August 2022 the Stable Diffusion model created by Stability.ai (in collaboration with CompVis group in Munich) was first released making it possible to create AI generated images using open-source software. There were payed providers on the market before like Midjourney, Dall-E or Dreamstudio but with the release of Stable Diffusion the creation of has become completely free provided you own a PC or laptop and a decent graphics card with at least 6GB of VRAM. These requirements are much lower compared to all of the other competitors making it a very hardware-friendly model in comparison.
Undoubtedly, this advancement affects not only photography but also various other creative fields. Can AI produce images that can effectively rival those of photography’s seasoned experts? Is AI slowly stealing jobs? In this blog post I will try to show you what you need to try this yourself, show examples and tips and provide some food for thought. I will concentrate on text-to-image generation although the model is capable of much much more like image-to-image or inpainting transformations.
Possibilities
Since the release the internet exploded with images causing lots of discussions regarding the topic of copyright infringements as well as ethical implications this free AI technology creates. Stable diffusion (especially v1.5) is extremely good at copying the style of the work of certain artists like for instance Greg Rutkowski (https://rutkowski.artstation.com/) or Michal Karcz (https://www.michalkarcz.com/parallelworlds). Generating images similar to those styles has become easy and so far there is no general usage restriction of the images generated. Other very popular artists who’s work is popular within the growing community are Jean Giraud-Moebius, Simon Stålenhag, Gerald Brom or even Banksy.
How does it work?
Without going into detail and simply speaking the model is trained by adding noise to training data (all sorts of images) and by doing so it learns how to recover image data by inverting this noising process. The generation of images using text prompts is possible because the model was trained on 5 billion image-text pairs from the internet. The connection between the image and descriptive text elements is done using the alt texts. This is an extremely simplified explanation and for sure not 100% accurate but you get the idea. It’s important to understand that the model does not merely copy or collage the pictures it was trained on but transforms them into something new using the prompts stated.
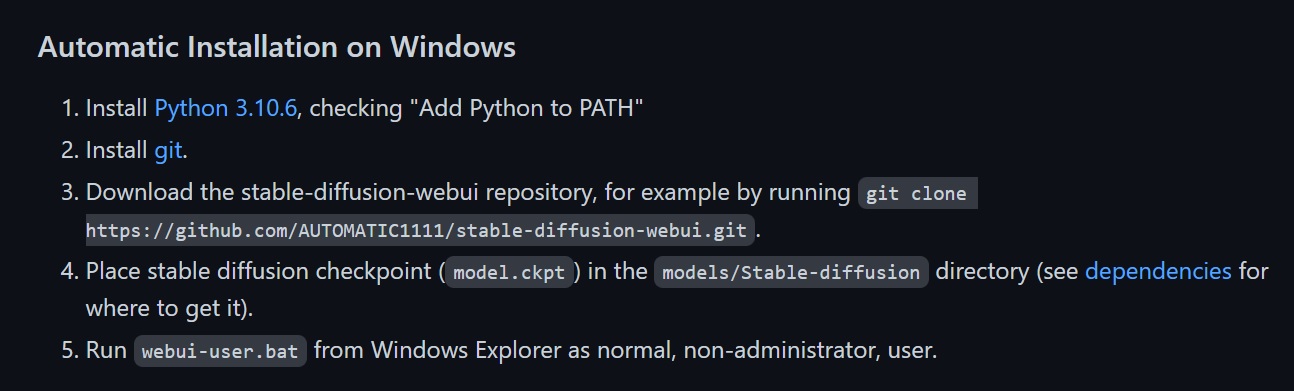
How to install Stable Diffusion on Windows 10 & 11?
Install the latest version of Automatic1111 Web-UI (https://github.com/AUTOMATIC1111/stable-diffusion-webui) and follow installation instructions 1, 2 and 3. When installing Python don’t forget to add Python to the path when the option displays during installation. Everything else is done automatically. The GIT installation can be done leaving everything set to default. Just click next during each installation step. For step 3 press the Windows-Key, type “cmd” and press enter. The Windows command prompt opens. Paste the command from step 3 (“git clone https://github.com/AUTOMATIC1111…”) into the command prompt. Press enter and wait until the installation is completed.
Installation Steps
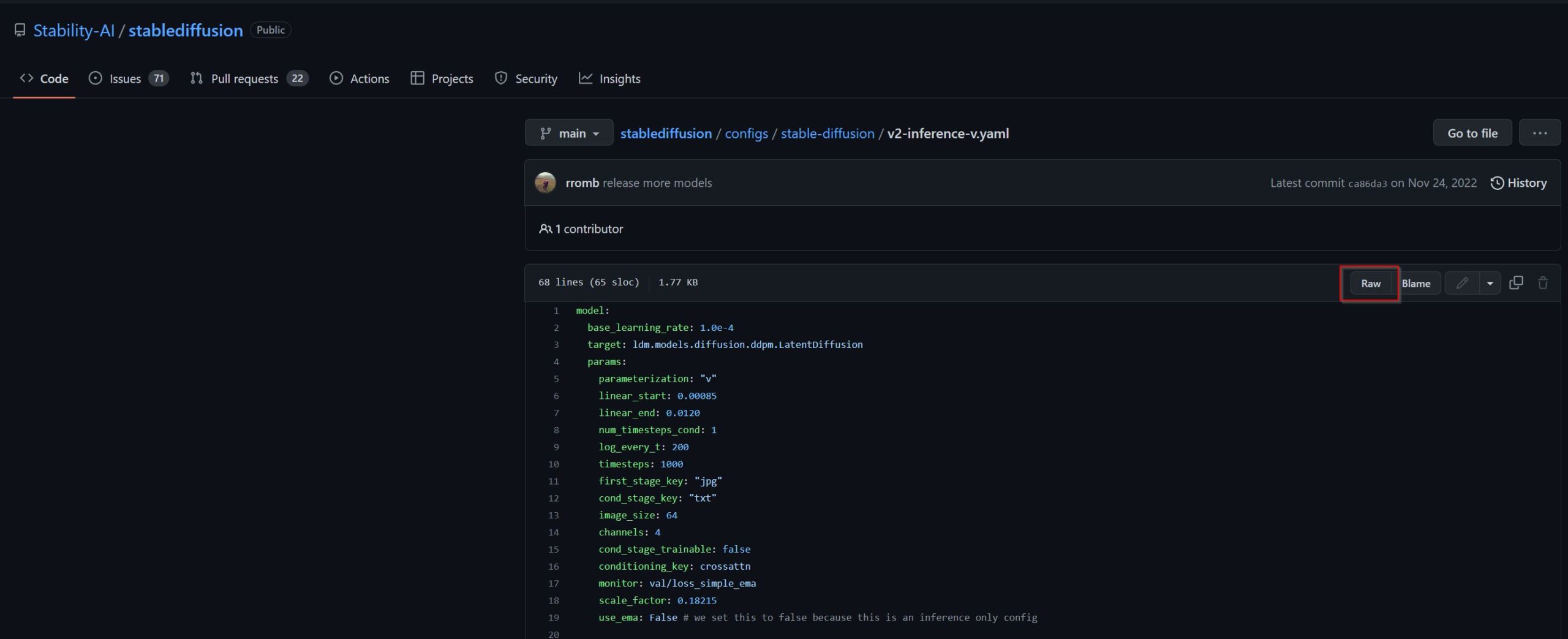
2. Next, download the file “v2-1_768-ema-pruned.ckpt” which is the model for generation in version 2.1. Follow this link: (v2-1_768-ema-pruned.ckpt)
Click on RAW and then right click and “save as” to save YAML file
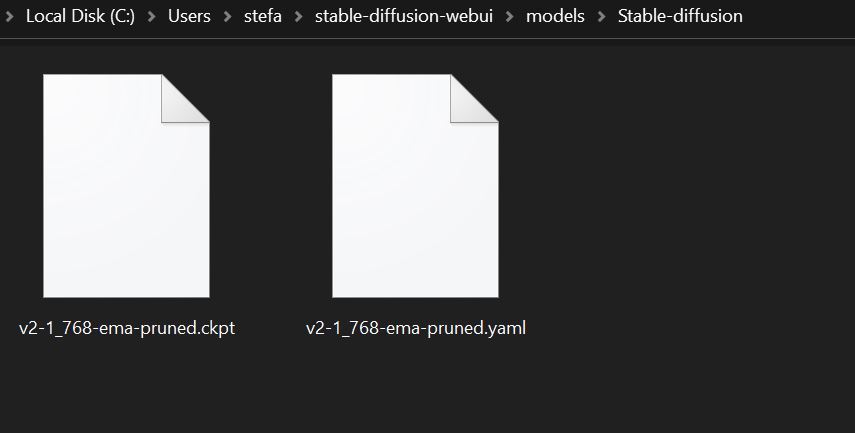
4. Move both files (model and yaml file) to the models folder of your Web UI installation. By default on Windows that is: Users > local user > stable-diffusion-webui > models > Stable-diffusion
The installation folder of stable diffusion Web UI should look like this now
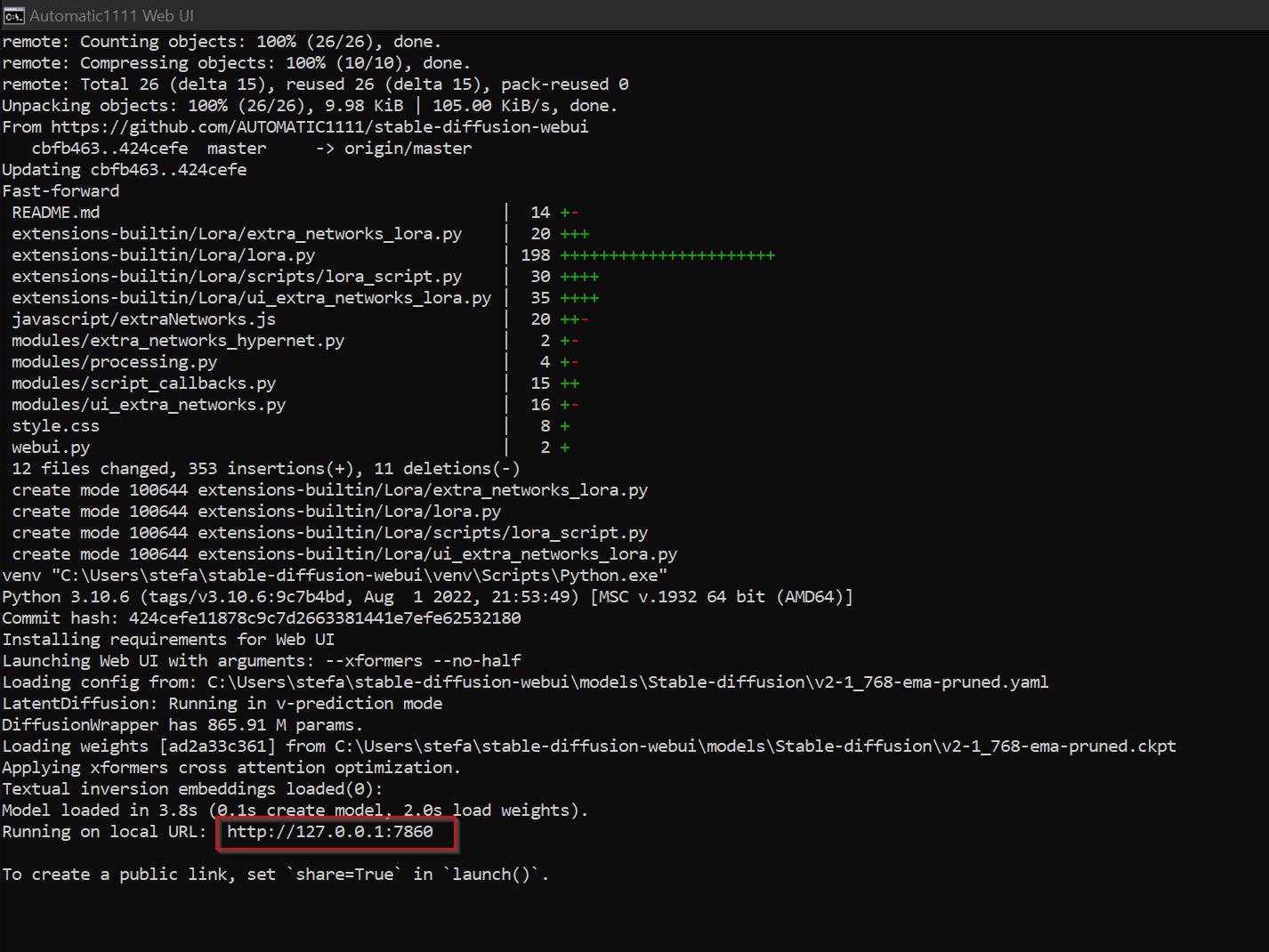
6. Start Web UI by double-clicking on file “webui-user.bat” in the installation directory. After that copy the address shown into your web browser and you’re ready to go!
Copy this into your browser
If you want to switch between models (e.g. 1.5 or 2.1) download both the model (v1-5-pruned-emaonly.ckpt) and YAML file (v1-inference.yaml) for version 1.5, rename YAML file and put both files additionally in the same directory. You can switch between all models but in this directory after restarting in the top left corner of the UI.
How to use the interface?
Web UI Overview
Promt
The prompt specifies what you want to see in the final image. The heart and soul of the text2img process. More on that further below.
Negative promt
Right below enter negative prompts. At least three or four to improve image quality. This is very important especially when using the 2.1 model.
Width & Height
The model was trained on 768×768 data so you will get the best result using a square format. I’ve experimented with 3:2 images using 512×768 for portraits or increased resolution images of 1536×1024 for landscapes (more VRAM is needed though) which worked well most of the time too.
Sampler
There are lots of different opinions which sampler works best for which purpose. Some say Heun is best for landscapes and others say DPM++ 2M Karras is best for portraits txt2img. I think this is part of the experimentation process. In general a value between 20 and 40 is where you’re able to get good results. Some samplers can work with higher settings to add more fine details depending on the subject whereas some other samplers need less iterations to generate something viable.
CFG Scale The abbreviation means “Classifier Free Guidance – Scale” and it’s the parameter to setup how much the model should stick to the prompt. A value between 5 and 15 works best in my opinion. Start with 7 and increase from there. Avoid extreme values on both the lower and upper end of the scale.
Seed The random seed determines the noise image the model starts with. -1 means random noise. If you generated a great image you like which is lacking some detail or needs to be fine tuned enter the seed (displayed under the generated image) again and re-render with slightly different settings (or use inpainting to optimize certain areas specifically).
Restore faces
Stable Diffusion has serious issues with faces and especially eyes. This function works magic to faces and is a must for portraits. In order to turn it on, just tick the checkbox. After that check the settings. Go to Settings tab, under “face restoration model”, select CodeFormer and leave the value to default.
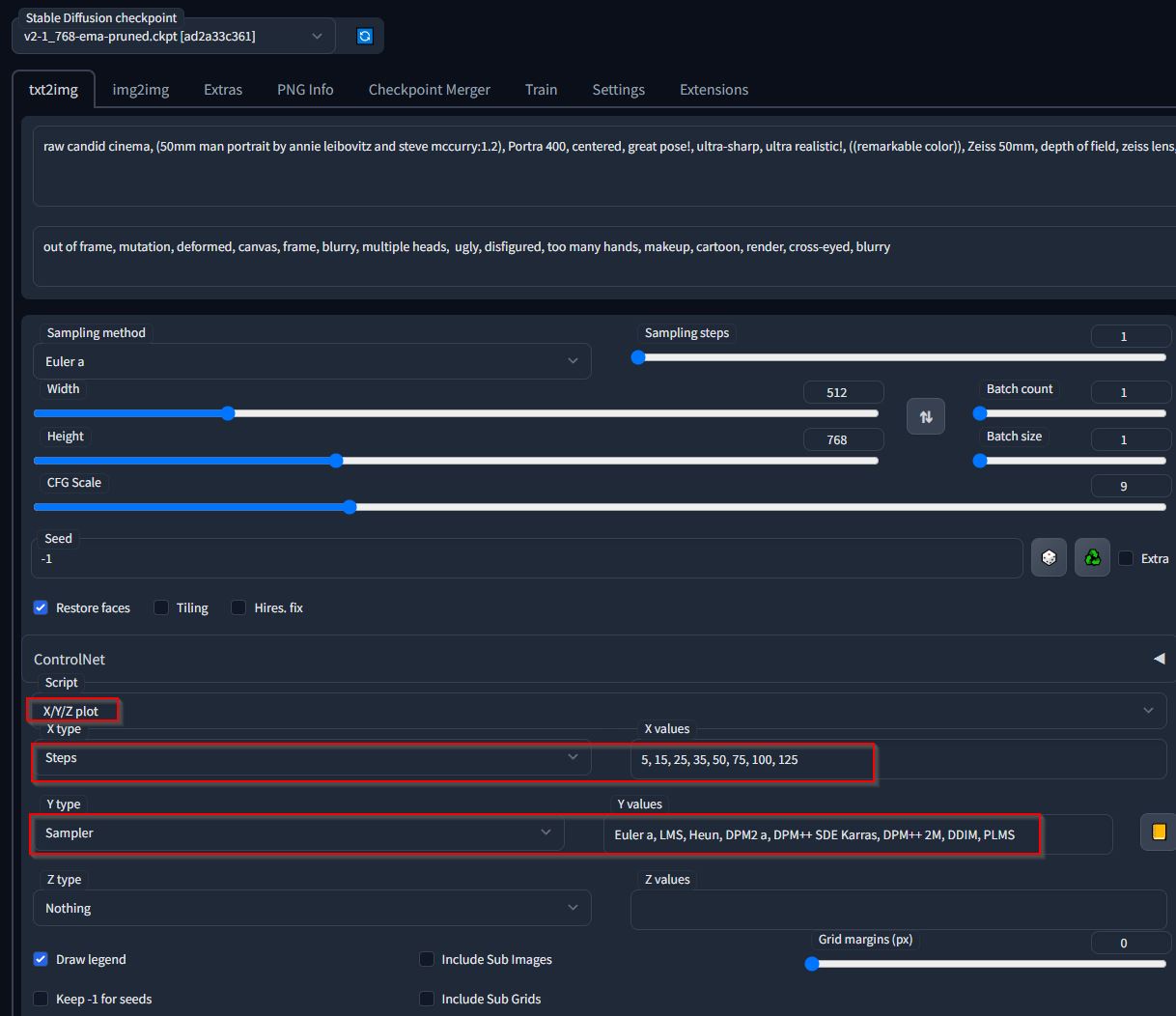
Sampler Steps Comparison
This example shows the difference between the samplers at certain step ranges for a portrait prompt. I utilized the X,Y,Z plot function with 8 unique step values and 8 distinct samplers on a fixed prompt and CFG (9). This yielded a singular comprehensive image that displays the various outcomes side by side for comparison.
The Prompt is the most important parameter. Be detailed and specific. Some people end up using lots and lots of different prompts to achieve certain results. The initial words in the prompt have a greater influence on the outcome than the subsequent words. It’s also possible to use factors for the words:
More attention to word -> ((word))
Factor 2 attention -> (word:2)
Increase attention to word -> word! or word!!
In my opinion the biggest differences in the results happen when changing the style requested in the prompt. You’ll find some more examples below. To get inspiration check the following links. There are numerous different examples of subjects and styles available on e.g. Lexica (https://lexica.art/), PlaygroundAI (https://playgroundai.com/) or Prompthero (https://prompthero.com/). If you like a certain image check the prompts and seeds in the metadata and try render your own images based on that style or subject.
Also check out these links for artist style studies. You’ll be surprised how good the results are if you make sure to include the artist names in the prompt.
Portrait (set a portrait aspect ratio in the width/height settings) Portrait photo (as first prompt for humans), standing, in a cathedral, looking away, serious eyes, hard rim lighting photography, 35mm portrait photography, wide angle, full-body shot, raw candid cinema, woman portrait, ultra realistic!, ((remarkable color)), Portra 400 (Analog film type), vivacious (in the end of the prompt), good pose
Historical and realistic photos Historical photo, associated press, high resolution scan
Drawings Cartoon, editorial illustration, new york times cartoon
Increase quality Award – winning photograph, masterpiece, award winning
Food PBR, photonic crystal, physically based rendering, ray-tracing, volume-marching, global Illumination, subsurface scattering, iridescence, opalescence, diffraction color
3D renders & realism Unreal engine, octane render, bokeh, vray, houdini render, quixel megascans, arnold render, 8k uhd, raytracing, cgi, lumen reflections, cgsociety, ultra realistic, 100mm, film photography, dslr, cinema4d, studio quality, film grain
Specific style Analog photo, portra 400, portra 800, polaroid, motion blur, fisheye, ultra-wide angle, macro photography, overglaze, volumetric fog, depth of field (or dof), silhouette, motion lines, color page, halftone, character design, concept art, symmetry, trending on dribbble (for vector graphics), precise lineart
Digital art Digital painting, trending on artstation, golden ratio, evocative, official art, award winning, shiny, smooth, surreal, divine, celestial, elegant, oil painting (works for almost all painting styles), soft, fascinating, fine art, keyvisual
Special lighting Volumetric lighting, bloom, glowing, god rays, backlighting, hard shadows, studio lighting, soft lighting, diffused lighting, rim lighting, , specular lighting, cinematic lighting, luminescence, translucency, subsurface scattering, global illumination, indirect light, radiant light rays, bioluminescent details, ektachrome, shimmering light, halo, iridescent, caustics
Negative Prompts
Negative prompting is very important with model 2.1, way more than with version 1.5. Without negative prompts it’s difficult to get good results.
A negative prompt is a set of negative words in order to exclude certain attributes of the result. It is possible to exclude styles like cartoon or counter against portraits with multiple heads or limbs on the model which happens very often. Sometimes it helps to put more emphasis on attributes which still occur in the result or simply repeat the negative prompt multiple times.
Negative prompts for portraits: Bad anatomy, bad eyes, cross-eye, bad hands, bad proportions, cloned face, deformed, disfigured, double head, extra arms, extra digit, extra heads, extra legs, extra limbs, extra fingers, fewer digits, gross proportions, malformed limbs, missing arms, missing fingers, missing legs, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck, mutated, mutated hands, poorly drawn face, poorly drawn hands, too many fingers, ugly eyes, black and white, blurry, boring, confusing, cropped, distorted, multiple people, noisy, out of focus, out of frame, out of shot, oversaturated, error, fake, glitchy, double face, double body, stacked body, conjoined, siamese twin, double faces
Negative prompts for general usage: Lowres, low quality, split, worst quality, fonts, logo, signature, username, watermark, jpeg artifacts, error, cropped, text, ugly, duplicate!, blurry, writing, letters, texts, stacked background, simple background (for landscapes), canvas frame, bad art, weird colors, photoshop, video game, tiling, out of frame
Workflow tips
To maximize the benefits of this tool and save time, I recommend to begin with a sampler that produces a consistent outcome with fewer steps, such as “Euler a”, and start with a low resolution setting and 20 to 25 steps.
Try a high number of batches in the first run and compare the results. If you like one specific image safe the seed and continue with that seed for the next iterations with different samplers and higher step counts.
When finished with the generation i recommend to upscale the images using the function “send to extras” as the last step. It’s possible to upscale first (after selection of the candidates for optimization) but this saves a lot of time as the render process slows down considerably when using larger images. Try different upscalers too. LDSR is great but slow, SwinIR is good but sometimes a little too sharp.
Promt examples and output
Here are some examples I created. The prompts and render settings can be found in the image description (if description does not show click on the image once). All images are unedited directly out of the WebUI.
Photograph of a tiger, in the jungle
Photograph of a tiger, in the jungle, hyper realistic, 8k, incredibly detailed, animal, 50mm zeiss, sharp
Negative prompt: low res, leopard, text, bad quality, jpg artefacts, blurry
Steps: 50, Sampler: Heun, CFG scale: 7.5, Seed: 2952963050, Size: 768×768, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned, Denoising strength: 0.7, Hires upscale: 1.75, Hires steps: 50, Hires upscaler: Latent
Painting of Mondrian, Ultra sharp, 8k
Painting of Mondrian, Ultra sharp, 8k
Negative prompt: blurry, error, jpg artefacts, signature, watermark, frame, out of frame
Steps: 50, Sampler: Euler a, CFG scale: 6, Seed: 2816330844, Size: 768×768, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned
ultra realistic illustration of immortal neuron, alien room, intricate, scifi, unique landscape, highly detailed, singularity, cybernetic, energy spheres, thought provoking, masterpiece, digital painting, artstation, concept art, smooth, sharp focus, highly detailed, art by roberto digiglio and furio tedeschi and filippo ubertino
Negative prompt: blurry, lowres, low quality, split, worst quality, fonts, logo, signature, username, watermark, jpeg artifacts, error, cropped, text, ugly!
Steps: 50, Sampler: DPM++ 2M, CFG scale: 8, Seed: 657298053, Size: 512×512, Model hash: cc6cb27103, Model: v1-5-pruned-emaonly, Denoising strength: 0.5, Hires upscale: 3, Hires upscaler: SwinIR_4x
A dream of a distant galaxy, by Caspar David Friedrich
A dream of a distant galaxy, by Caspar David Friedrich, matte painting trending on artstation HQ
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 2561312158, Size: 512×512, Model hash: fe4efff1e1, Model: model
Astronaut looking at a nebula
Astronaut looking at a nebula , digital art , trending on artstation , hyperdetailed , matte painting , CGSociety
Negative prompt: ugly, disfigured, deformed, too many hands, makeup, cartoon, render
Steps: 96, Sampler: DDIM, CFG scale: 12, Seed: 1831069115, Size: 768×768, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned
A landscape by Simon Stalenhag
A landscape by Simon Stalenhag of a very large realistic highly detailed imposing robotic mechanical cat, moody, dark, fog!, stranded alone and roaming in the chaos across a depressing abandoned post – apocalyptic landscape, postapocalyptic, artstation trending, beautiful art landscape, detailed simon stalenhag landscape
Negative prompt: lowres, low quality, split, worst quality, fonts, logo, signature, username, watermark, jpeg artifacts, error, cropped, text, ugly, duplicate!, blurry, writing, letters, texts, stacked background
Steps: 50, Sampler: Euler a, CFG scale: 8, Seed: 91510922, Size: 1024×864, Model hash: cc6cb27103, Model: v1-5-pruned-emaonly, Denoising strength: 0.6, Hires upscale: 1.5, Hires steps: 50, Hires upscaler: Latent
Alien temple, beautiful landscape, nier automata, protoss!!, machine planet, glass obelisks!!, glow, mothership in the sky
Alien temple, beautiful landscape, nier automata, protoss!!, machine planet, glass obelisks!!, glow, mothership in the sky, pink sun, tropical forest, colorful light, advanced technology, cinematic lighting, warframe, epic scale, highly detailed, masterpiece, art by bastien grivet and darwin cellis and jan urschel
Negative prompt: blurry, duplicates, lowres, low quality, split, worst quality, fonts, logo, signature, username, watermark, jpeg artifacts, error, cropped, text, ugly!
Steps: 35, Sampler: Euler a, CFG scale: 12, Seed: 1846863085, Size: 512×640, Model hash: cc6cb27103, Model: v1-5-pruned-emaonly, Denoising strength: 0.6, Hires upscale: 4, Hires steps: 35, Hires upscaler: Latent
A landscape with a dystopian spaceport, rain, oily puddles, mechanics, crates and parts on the ground, overalls
A landscape with a dystopian spaceport, rain, oily puddles, mechanics, crates and parts on the ground, overalls, people are talking in the foreground, in the background a spacecraft is landing, thrusters, glow, volumetric lighting, ray lighting from top of frame, crepuscular ray lighting from above, dynamic lighting, muted colors, by Greg rutkowski, thomas kinkade, Andreas rocha, john howe, pixar, f16, hd, 4k
Negative prompt: blurry!!, Lowres, low quality, split, worst quality, fonts, logo, signature, username, watermark, extra digit, jpeg artifacts, error, cropped, text, ugly, duplicate, writing, letters, texts, stacked background
Steps: 35, Sampler: DPM2 a, CFG scale: 13, Seed: 300482910, Size: 1024×512, Model hash: cc6cb27103, Model: v1-5-pruned-emaonly, Denoising strength: 0.7, Hires upscale: 2, Hires steps: 35, Hires upscaler: SwinIR_4x
Surface of Mars
Surface of mars, Rocks, beautiful light, ctane render, 8 k!, exploration, cinematic, trending on artstation, by beeple,hyper realistic!, 3 5 mm camera, unreal engine, hyper detailed, photo – realistic maximum detai, volumetric light, moody cinematic epic concept art, realistic matte painting, hyper photorealistic, concept art, volumetric light, cinematic epic, octane render, 8 k, corona render, movie concept art, octane render, 8 k, corona render, cinematic, trending on artstation, movie concept art, cinematic composition, ultra – detailed, realistic, hyper – realistic, volumetric lighting, 8 k
Negative prompt: lowres, worst quality, jpeg artifacts, cropped
Steps: 132, Sampler: LMS, CFG scale: 16, Seed: 2356879792, Size: 512×512, Model hash: fe4efff1e1, Model: model
Lush farmland outside a beautiful elven city
Lush farmland outside a beautiful elven city made of white marble, anime, lush trees, a fantasy digital painting by greg rutkowski and james gurney, trending on artstation, highly detailed, cgsociety
Negative prompt: lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate
Steps: 50, Sampler: Heun, CFG scale: 7, Seed: 463781001, Size: 768×512, Model hash: cc6cb27103, Model: v1-5-pruned-emaonly, Denoising strength: 0.7, Hires upscale: 2, Hires steps: 50, Hires upscaler: SwinIR_4x
Excellent painted daemon in a wide epic beautiful landscape III
Excellent painted daemon in a wide epic beautiful landscape somewhere in africa with fluffy clouds, painted by hans fredrik gude, greg rutkowksi, craig mullins and artgerm, masterpiece, 4k, ultra realistic highly detailed oil painting
Negative prompt: lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate
Steps: 50, Sampler: Euler a, CFG scale: 7, Seed: 1726153108, Size: 896×512, Model hash: cc6cb27103, Model: v1-5-pruned-emaonly, Denoising strength: 0.7, Hires upscale: 2, Hires steps: 50, Hires upscaler: SwinIR_4x
Beautiful render of an alien landscape
Beautiful render of an alien landscape, iridescent tesseracts, geometric shapes, fractals, glass, unreal engine, first light, majestic mountains, lake, lush grass, dramatic clouds, encampment, soft light, by greg rutkowski, cgsociety
Steps: 50, Sampler: Euler a, CFG scale: 7, Seed: 3747882285, Size: 1024×512, Model hash: cc6cb27103, Model: v1-5-pruned-emaonly, Denoising strength: 0.6, Hires upscale: 2, Hires steps: 50, Hires upscaler: SwinIR_4x
Alien spaceship saucer flying, abducting a human in the forest at night,((intricate lights and design)), art by midjourney and greg rutkowski, epic details, highly detailed, trending on artstation, 8k, cinematic, (Intricate), (High Detail), Sharp focus, dramatic, fantasy
Negative prompt: lowres, text, stacked background, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate
Steps: 10, Sampler: Euler, CFG scale: 8, Seed: 4148824428, Size: 1024×576, Model hash: cc6cb27103, Model: v1-5-pruned-emaonly, Denoising strength: 0.6, Hires upscale: 2, Hires steps: 50, Hires upscaler: Latent
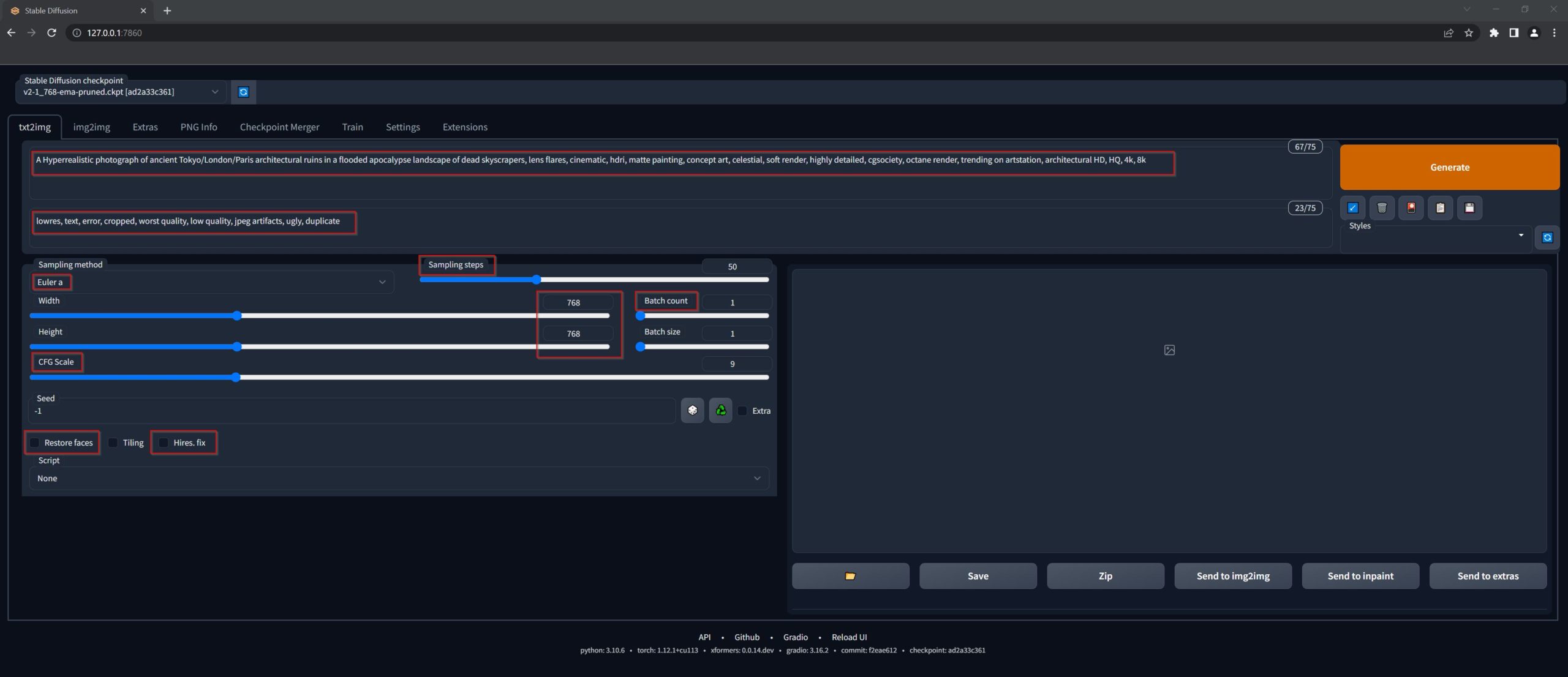
A Hyperrealistic photograph of ancient Tokyo architectural ruins in a flooded apocalypse
A Hyperrealistic photograph of ancient Tokyo/London/Paris architectural ruins in a flooded apocalypse landscape of dead skyscrapers, lens flares, 8k!, cinematic, hdri, celestial, soft render, highly detailed, cgsociety, octane render, trending on artstation, architectural HD, HQ, 4k
Negative prompt: lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate
Steps: 50, Sampler: Heun, CFG scale: 12, Seed: 175263023, Size: 1536×1024, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned
Cyberpunk mercenary face portrait in foreground, inside futuristic space dock with space ships and people, futuristic epic tall buildings in background
(cyberpunk mercenary face portrait in foreground, inside futuristic space dock with space ships and people, futuristic epic tall buildings in background, saturated swirling colorful pink yellow green blue:1.4), Digital art, glow effects, hand drawn, render, 8k, octane render, cinema 4d, blender, dark, atmospheric 4k ultra detailed, cinematic sensual, sharp focus, humorous illustration, big depth of field, masterpiece, colors, 3d octane render, 4k, concept art, trending on artstation, hyperrealistic, vivid colors, modelshoot style, (extremely detailed CG unity 8k wallpaper), professional majestic oil paiting by Ed Blinkey, Atey Ghailan, Studio Ghibli, by Jeremy Mann, Greg Manchess, Antonio Moro, treding on ArtStation, trending on CGSociety, Intricate, High Detail, Sharp focus, dramatic, photorealistic paiting art by midjourny and greg rutkowski
Negative prompt: logo, Glasses, Watermark, bad artist, blur, blurry, text, b&W, 3d, bad art, poorly drawn, disfigured, deformed, extra limbs, ugly hands, extra fingers, canvas frame, cartoon, 3d, disfigured, bad art, deformed, extra limbs, weird colors, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn face, mutation, deformed, ugly, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, out of frame, ugly, extra limbs, bad anatomy, gross proportions, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, bad art, bad anatomy, 3d render
Steps: 25, Sampler: Euler a, CFG scale: 7, Seed: 1832578085, Size: 720×405, Model hash: 6a21b428a3, Model: protogenX58RebuiltScifi_10
Painting of a Fallout scenery at metro
Painting of a post scenery at metro, Man standing in fallout power armor, ultra realistic, concept art, intricate details, eerie, highly detailed, fallout, metro 2033, wasteland, photorealistic!, octane render, 8 k, unreal engine 5, art by artgerm and greg rutkowski and alphonse mucha
Negative prompt: lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate
Steps: 50, Sampler: Heun, CFG scale: 7, Seed: 2470607565, Size: 1024×683, Model hash: cc6cb27103, Model: v1-5-pruned-emaonly
A lake surrounded by tall pine trees with a mountain in the distant background, some grass in the first plan, a detailed matte painting by senior environment artist, shutterstock contest winner, photorealism, diffuse sunlights, rendered in unreal engine, matte painting, anamorphic lens flare, photo taken with canon 5d and a wild angle lens
Negative prompt: lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate
Steps: 50, Sampler: Heun, CFG scale: 9, Seed: 2203288774, Size: 1024×683, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned, Denoising strength: 0.7, Hires upscale: 1.5, Hires steps: 50, Hires upscaler: SwinIR_4x
Lush farmland outside a beautiful elven city
Lush farmland outside a beautiful elven city made of white marble, anime, lush trees, a fantasy digital painting by greg rutkowski and james gurney, trending on artstation, highly detailed, cgsociety
Negative prompt: lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate
Steps: 50, Sampler: Heun, CFG scale: 7, Seed: 463781002, Size: 768×512, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned, Denoising strength: 0.7, Hires upscale: 2, Hires steps: 50, Hires upscaler: SwinIR_4x
A Landscape by Simon Stalenhag
A landscape by simon stalenhag of a very large realistic highly detailed imposing robotic mechanical cat, stranded alone and roaming in the chaos across a depressing abandoned post – apocalyptic landscape, post – apocalyptic corrupted themes, artstation trending, beautiful art landscape, detailed simon stalenhag landscape
Negative prompt: lowres, low quality, split, worst quality, fonts, logo, signature, username, watermark, jpeg artifacts, error, cropped, text, ugly, duplicate!, blurry, writing, letters, texts, stacked background
Steps: 50, Sampler: DPM2 a, CFG scale: 8, Seed: 3288730740, Size: 1536×864, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned
Old harbour, tone mapped II
Old harbour, tone mapped, shiny, intricate, cinematic lighting, highly detailed, digital painting, artstation, concept art, smooth, sharp focus, illustration, art by terry moore and greg rutkowski and alphonse mucha
Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name
Steps: 96, Sampler: LMS, CFG scale: 12, Seed: 2163230395, Size: 1536×1024, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned
Photo of a tree on a forest landscape, harsh flash
Negative prompt: blurry, duplicates, lowres, low quality, split, worst quality, fonts, logo, signature, username, watermark, jpeg artifacts, error, cropped, text, ugly!
Steps: 30, Sampler: DPM++ 2M, CFG scale: 7, Seed: 2934217836, Size: 512×512, Model hash: cc6cb27103, Model: v1-5-pruned-emaonly, Denoising strength: 0.6, Hires upscale: 4, Hires upscaler: SwinIR_4x
Wooden Mill in Forest,
Wooden Mill in forest, Sunset, Small Waterfall, River, Hyper realistic, 8k, Photorealistic, Sharp, Authentic, Real Photo
Steps: 150, Sampler: LMS, CFG scale: 7, Seed: 3779523585, Size: 1600×900, Model hash: fe4efff1e1, Model: model
Landscape, Seascape & Waves
Landscape, Seascape, Waves, Sea stacks, Sunset, Ultra realistic, 8k, Photorealistic, Sharp, Authentic, Real Photo
Steps: 150, Sampler: LMS, CFG scale: 7, Seed: 2815006186, Size: 1600×900, Model hash: fe4efff1e1, Model: model
Glass in the sky, beautiful landscape, highly detailed, machine planet, buildings, prismatic, alien utopia, metallic surface
glass in the sky, beautiful landscape, highly detailed, machine planet, buildings, prismatic, alien utopia, metallic surface, diamond trees, advanced technology, nier automata, cinematic lighting, sharp focus, artstation, intricate, masterpiece, art by maria panfilova and dylan kowalski and huifeng huang
Negative prompt: blurry!!, Lowres, low quality, split, worst quality, fonts, logo, signature, username, watermark, extra digit, jpeg artifacts, error, cropped, text, ugly, duplicate, writing, letters, texts, stacked background
Steps: 35, Sampler: Heun, CFG scale: 7, Seed: 1471111696, Size: 768×1024, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned, Denoising strength: 0.6, Hires upscale: 1.5, Hires steps: 35, Hires upscaler: SwinIR_4x
Photography of a landscape with a lake, centered path leads to the lighthouse, one detailed Lighthouse in the middle
photography of a landscape with a lake, centered path leads to the lighthouse, one detailed Lighthouse in the middle, (blue dark tones:1.2), leveled horizon, Path of rocks, 8k, highly detailed rock texture, sharp focus, trending in 500px, Alfred Parsons, Max Rive, Arthur Adams, Dustin LeFevre
Negative prompt: multiple lighthouses, blurry, ugly, text, logo
Steps: 40, Sampler: DPM++ SDE Karras, CFG scale: 9, Seed: 3749358384, Size: 1536×1024, Model hash: 6a21b428a3, Model: protogenX58RebuiltScifi_10
Ancient Malaysian Temple
A Hyperrealistic photograph of ancient Malaysian architectural ruins in Borneo’s East Malaysia, lens flares, cinematic, hdri, matte painting, concept art, celestial, soft render, highly detailed, cgsociety, octane render, trending on artstation, architectural HD, HQ, 4k, 8k
Negative prompt: lowres, low quality, text, error, cropped, worst quality, jpeg artifacts, ugly, duplicate
Steps: 96, Sampler: LMS, CFG scale: 12, Seed: 511171999, Size: 768×768, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned
Portrait by Steve Mc Curry, raw candid, kodachrome 64, ultra sharp, beautiful light, highres, shallow depth of field
raw candid cinema, (50mm man portrait by annie leibovitz and steve mccurry:1.2), Portra 400, centered, great pose!, ultra-sharp, ultra realistic!, ((remarkable color)), Zeiss 50mm, depth of field, zeiss lens, beautiful light
Negative prompt: logo, Glasses, Watermark, bad artist, blur, blurry, text, b&W, 3d, bad art, poorly drawn, disfigured, deformed, extra limbs, ugly hands, extra fingers, canvas frame, cartoon, 3d, disfigured, bad art, deformed, extra limbs, weird colors, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn face, mutation, deformed, ugly, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, out of frame, ugly, extra limbs, bad anatomy, gross proportions, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, bad art, bad anatomy, 3d render
Steps: 5, Sampler: Euler a, CFG scale: 7, Seed: 2316265175, Face restoration: CodeFormer, Size: 512×768, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned
Raw candid cinema, woman portrait III
Raw candid cinema, woman portrait, ultra realistic!, ((remarkable color))
Negative prompt: ugly, disfigured, deformed, too many hands, makeup, cartoon, render
Steps: 96, Sampler: Euler a, CFG scale: 7, Seed: 324913401, Size: 768×512, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned, Denoising strength: 0, Hires upscale: 2, Hires steps: 96, Hires upscaler: None
Young Afghan girl with green eyes, Upper body portrait,stone wall in the background
Young Afghan girl with green eyes, Upper body portrait,stone wall in the background, masterpiece, Steve McCurry!!, highres, shallow depth of field, Sharp focus, 8k, Cannon EOS 5D Mark III, 85mm, Cinematic, symmetry, Amazing photography, De-Noise, f 5.6 , 85mm, CineStill 800T, film photo, realistic portrait, round eyes, skin texture, soft natural lighting, Cinestill 800T, (8k wallpaper), perfect, masterpiece, highres, broad light, Sharp focus, natural lighting, masterpiece, 4K,, high quality, (big eyes)
Negative prompt: duplicate heads, lace, intricate, out of frame, out of shot, child, childlike, clipping, 3d, cartoon, 3dcg, doll, illustration, render, lowres, bad anatomy, bad hands, text, error
Steps: 30, Sampler: DPM2 a, CFG scale: 6, Seed: 281043492, Face restoration: CodeFormer, Size: 768×768, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned, Denoising strength: 0.6, Hires upscale: 1.75, Hires steps: 25, Hires upscaler: SwinIR_4x
Portrait of middle aged man with a beard
Portrait of middle aged man with a beard walk on the street of new york, monochrome, by charlotte grimm, natural light, detailed face, beautiful features, symmetrical, canon eos c 3 0 0, ƒ 1. 8, 3 5 mm, 8 k, medium – format print, half body shot
Negative prompt: lowres, low quality, cropped, split, worst quality, fonts, logo, signature, username, watermark, jpeg artifacts, error, text, ugly!, duplicate, blurry, writing, letters, texts
Steps: 50, Sampler: DPM adaptive, CFG scale: 7, Seed: 3685961945, Face restoration: CodeFormer, Size: 768×768, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned, Denoising strength: 0.7, Hires upscale: 1.5, Hires steps: 50, Hires upscaler: SwinIR_4x
Portrait of middle aged man with a beard II
Portrait of middle aged man with a beard walk on the street of new york, by charlotte grimm, natural light, detailed face, beautiful features, symmetrical, canon eos c 3 0 0, ƒ 1. 8, 3 5 mm, 8 k, medium – format print, half body shot
Negative prompt: lowres, low quality, cropped, split, worst quality, fonts, logo, signature, username, watermark, jpeg artifacts, error, text, ugly!, duplicate, blurry, writing, letters, texts
Steps: 50, Sampler: DPM adaptive, CFG scale: 7, Seed: 3685961952, Face restoration: CodeFormer, Size: 768×768, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned
Portrait photography of homeless by annie leibovitz
A portrait of a beautiful blonde woman, fine – art photography, soft portrait shot 8 k, mid length, ultrarealistic uhd faces
A portrait of a beautiful blonde woman, fine – art photography, soft portrait shot 8 k, mid length, ultrarealistic uhd faces, Rembrandt lighting, unsplash, kodak ultra max 800, 35 mm!, intricate, rembcasual pose, (centered symmetrical composition:1.2), stunning photos, masterpiece, centered composition
Negative prompt: canvas, frame, long neck!, B&W, closed eyes, ugly, duplicate, mutilated, (out of frame:1.4), extra fingers, mutated hands, poorly drawn hands, poorly drawn face
Steps: 25, Sampler: Euler a, CFG scale: 8, Seed: 1232062075, Face restoration: CodeFormer, Size: 512×768, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned
Raw candid cinema, woman portrait
Raw candid cinema, woman portrait, ultra realistic!, ((remarkable color))
Negative prompt: ugly, disfigured, deformed, too many hands, makeup, cartoon, render
Steps: 96, Sampler: DDIM, CFG scale: 12, Seed: 1864915809, Face restoration: CodeFormer, Size: 768×768, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned
Something to mention: The models used in this blog are the base models of Stable Diffusion. There are many many more different models for many different purposes out there.
Generally nothing is as constant as change in the field of AI. These models and UI’s change and advance very very quickly. While writing this article, an exciting opportunity has emerged with the introduction of Control Nets, which enable the manipulation of pose, lighting conditions, and even text during rendering. This breakthrough suggests that even more possibilities may be on the horizon.
For now there is no better way to generate high quality images than using Stable Diffusion and Control Nets. Check out this video of Sebastian Kamph a suberb YouTuber explaining the ue of Control Nets it in detail: https://www.youtube.com/watch?v=vFZgPyCJflE
Conclusions and Thoughts
So what do you think about all this? Ansel Adams, the renowned photographer, is credited with pioneering the technique of dodging and burning on analog film in the 1920s. He was even cutting out parts of the film negative using them in other photographs. So he was maybe the first to perform heavy photo manipulation. Isn’t AI just the next step in the world of photography? Regarding digital photography, AI has been here a while already. For example during the upscaling of photos, facial- and environment recognition software, photo manipulation like sky replacement, and much more. AI-powered editing tools and apps are more and more common. Soon there will be AI-powered DSLM’s.
So, will AI replace photographers and/or photography?
The Art Attack
As this is only the beginning the possibilities are endless. However, as stunning as the results maybe, I don’t think AI will replace professional photographers or digital artists even in the long run.
It is possible or even guaranteed that it could replace certain forms of photography, such as stock photography. Images which are used in marketing campaigns or information brochures. Everything that doesn’t need authenticity to incorporate value will be replaced in my opinion. Nevertheless it will take a long long time until professional photography such as fine-art photography could be seriously challenged. The value of a fine-art photograph or a certain style in a piece of digital art does not lie within the technical quality or ease of accessibility but within the craft of the creator using composition and imagination. Think of what work of art you would put on you wall at home. It will be something of personal value. Either you admire the abilities of the creator or you connect certain feelings with it. The same applies for the creation of movies or other artwork. There might be an even stronger focus on art that inherits certain unique attributes forcing the artists to be even more imaginative and innovational.
In terms of the changed situation for creators I believe that curation, coordination and human factors will become more and more important. For instance the coordination work of art directors will remain a huge factor. The social skills of wedding photographers will furthermore be their most valuable asset and the enhanced skills at post-processing and finetuning of images to satisfy certain needs will be more needed than ever.
AI has been showing promising results in winning various art contests recently, although its dominance may be temporary owing to its novelty factor, and it may not be able to compete with human creativity in the long run. It is often said that the use of this technology should be aimed at creating novel and valuable works of art or enhancing existing ones, rather than feeling threatened or constrained by it. This approach would lead to a positive and constructive path forward.
One topic remains critical however in my opinion: Copyright infringements. As Stable Diffusion was built on tons of copyrighted work of many artists yet doesn’t copy it directly the question is how to assess the legal position. Eventually it needs to be determined if the result has a derivative or transformative characteristic. As far as I understood the current class-action lawsuits running, they are based on exactly that distinction. It really depends on the case and usage and this is going to be a topic for the next decades rather than the next months I suppose.
The question of the nature of creativity is also under scrutiny, particularly regarding the attribution of creative output to a singular individual. It raises the question of who can be considered the true creator of a work: the person who programmed the software, the organization that trained the model, the AI system itself, or the individual utilizing it to generate output?
I envision that these tools will greatly enhance the efficiency of customer-artist interactions, streamlining the entire process and reducing the need for physical presence. This increased efficiency will enable artists to be more productive, resulting in higher quality output. Moreover, the availability of these tools may lead to a surge in small-scale indie game and design start-ups, which can now generate useful output at a faster rate and potentially improve the end result through iterative refinement during the interaction process.
Personally I found experimenting with this tool extremely interesting. I discovered artists like classical painters and modern digital artists I would never have learned about otherwise. Because of the unpredictability of the results the generation feels kind of like casting a spell. Some prompts work great while others don’t work at all. Referring back to the artists mentioned in the beginning of this article – their popularity apparently sky-rocketed after people found out they can use and adapt their styles quite well. Maybe it even helps those artists to sell more work instead of the opposite and maybe this attention will have a positive impact after all.